 SECRETA - Screen shots
SECRETA - Screen shots
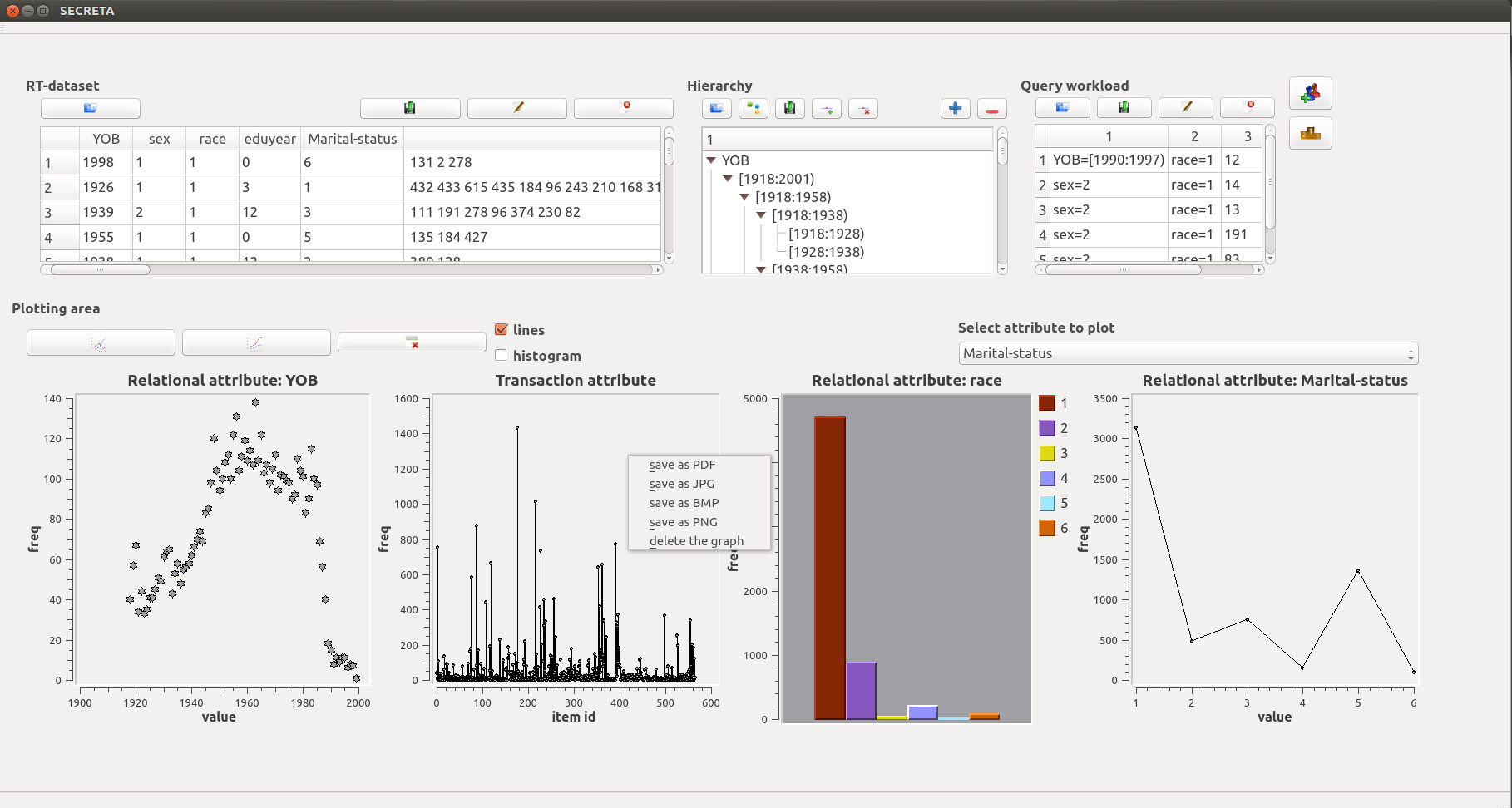 Main screen. The interface gives users the following capabilities. First, using the input area (top-left pane) of the interface, the user can load a dataset, with relational or transaction attributes, or an RT-dataset (i.e., a dataset with both relational and transaction attributes). SECRETA allows users to fully edit the loaded dataset, by editing attribute names and values. Second, the user can analyze the dataset by plotting histograms of the frequency of values in any attribute (bottom pane). Third, the user can load one or more predefined hierarchies from a file. Each hierarchy is fully browsable and editable, through the hierarchy area (top-mid pane). Fourth, the user can load a preconstructed query workload from a file, edit the query values using the query workload area (top-right pane). After performing these tasks, the user can enable either Evaluation or Comparison mode (using the buttons in the top-right pane).
Main screen. The interface gives users the following capabilities. First, using the input area (top-left pane) of the interface, the user can load a dataset, with relational or transaction attributes, or an RT-dataset (i.e., a dataset with both relational and transaction attributes). SECRETA allows users to fully edit the loaded dataset, by editing attribute names and values. Second, the user can analyze the dataset by plotting histograms of the frequency of values in any attribute (bottom pane). Third, the user can load one or more predefined hierarchies from a file. Each hierarchy is fully browsable and editable, through the hierarchy area (top-mid pane). Fourth, the user can load a preconstructed query workload from a file, edit the query values using the query workload area (top-right pane). After performing these tasks, the user can enable either Evaluation or Comparison mode (using the buttons in the top-right pane).
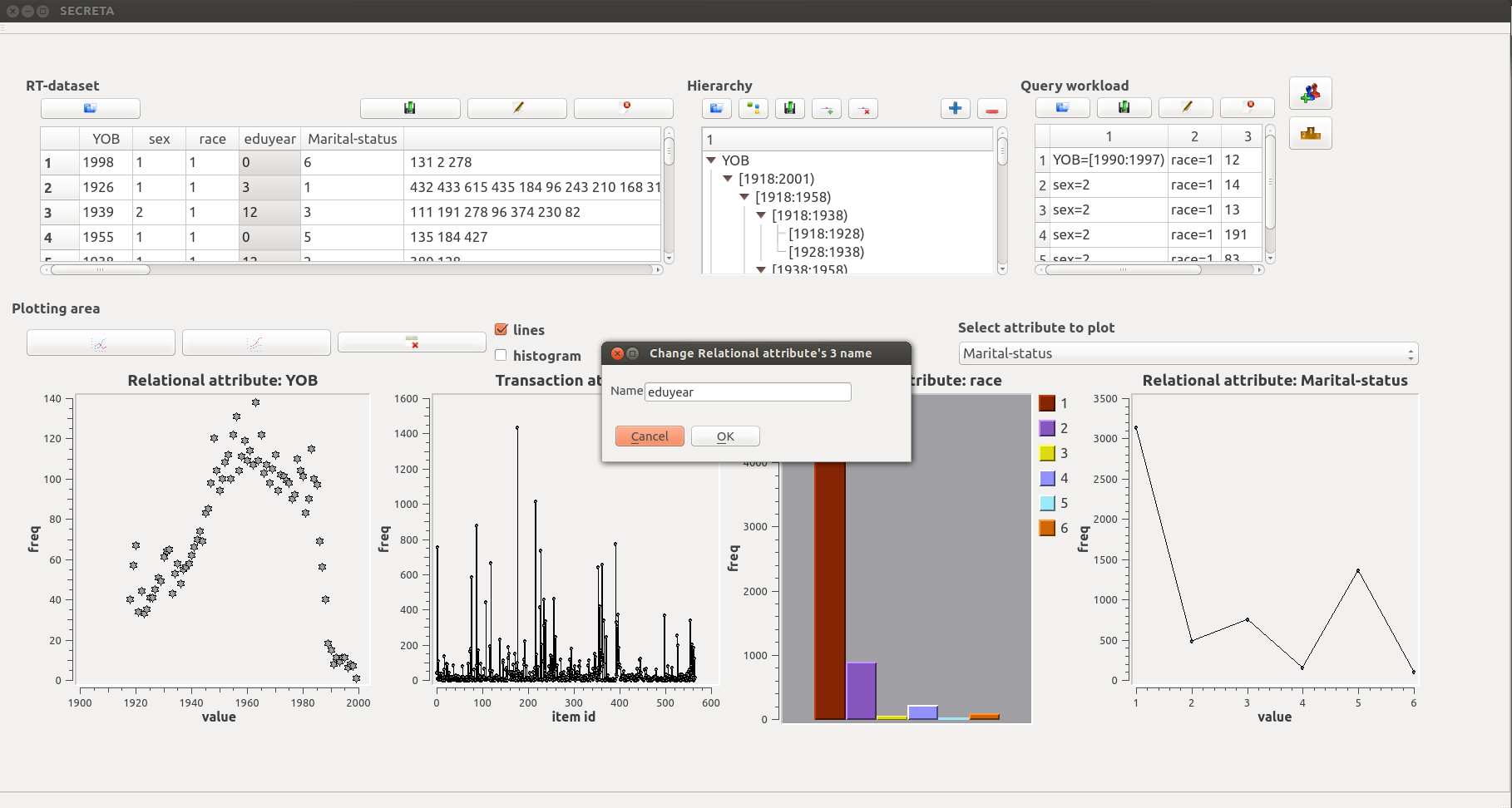 By double clicking an attribute's name in the input area, the users can edit the name of the selected attribute.
By double clicking an attribute's name in the input area, the users can edit the name of the selected attribute.
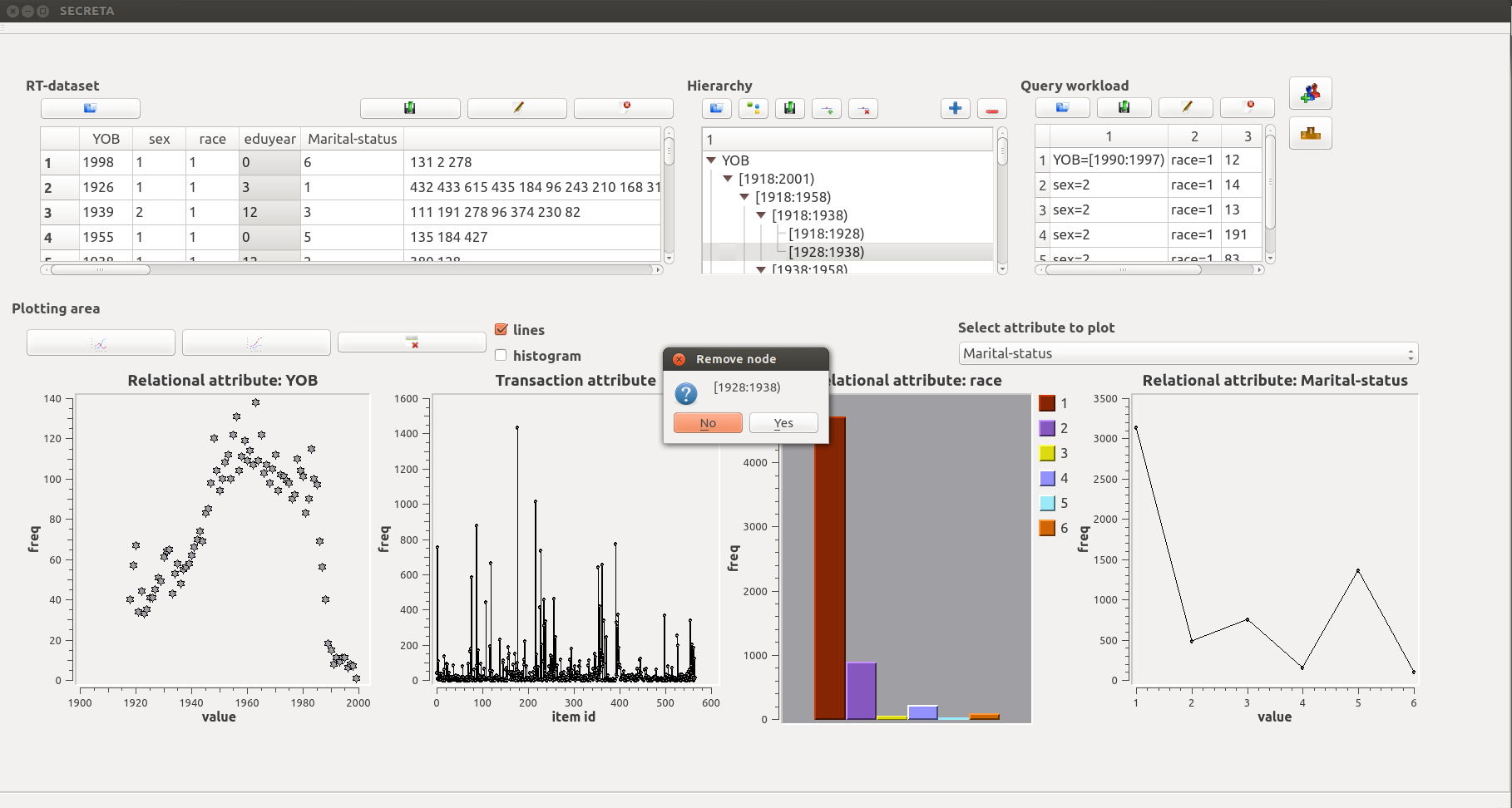
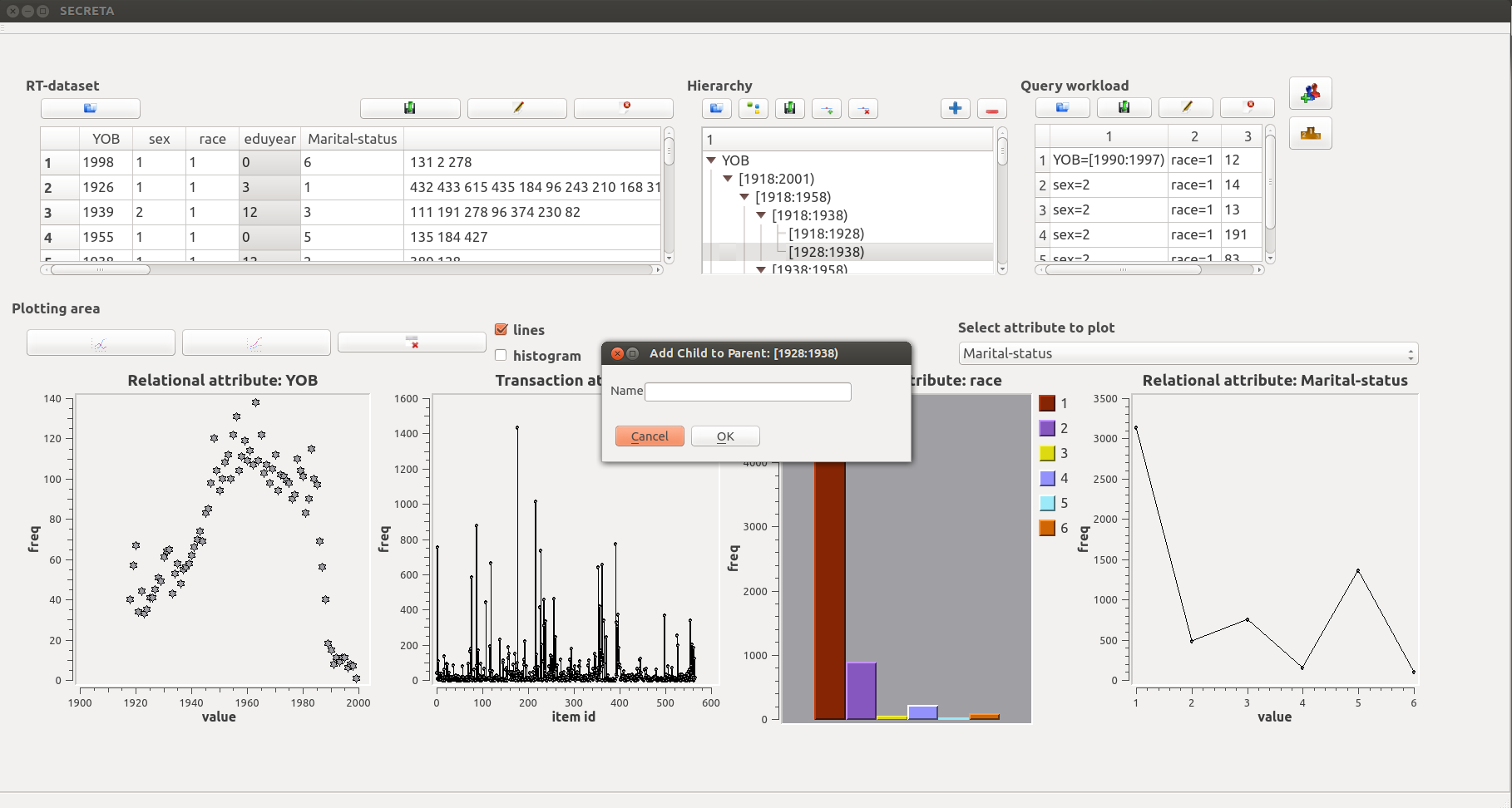 The Hierarchy area enables users to view, delete or insert nodes in a hierarchy. Hierarchies for either relational or transaction attributes can also be generated automatically, using built-in algorithms.
The Hierarchy area enables users to view, delete or insert nodes in a hierarchy. Hierarchies for either relational or transaction attributes can also be generated automatically, using built-in algorithms.
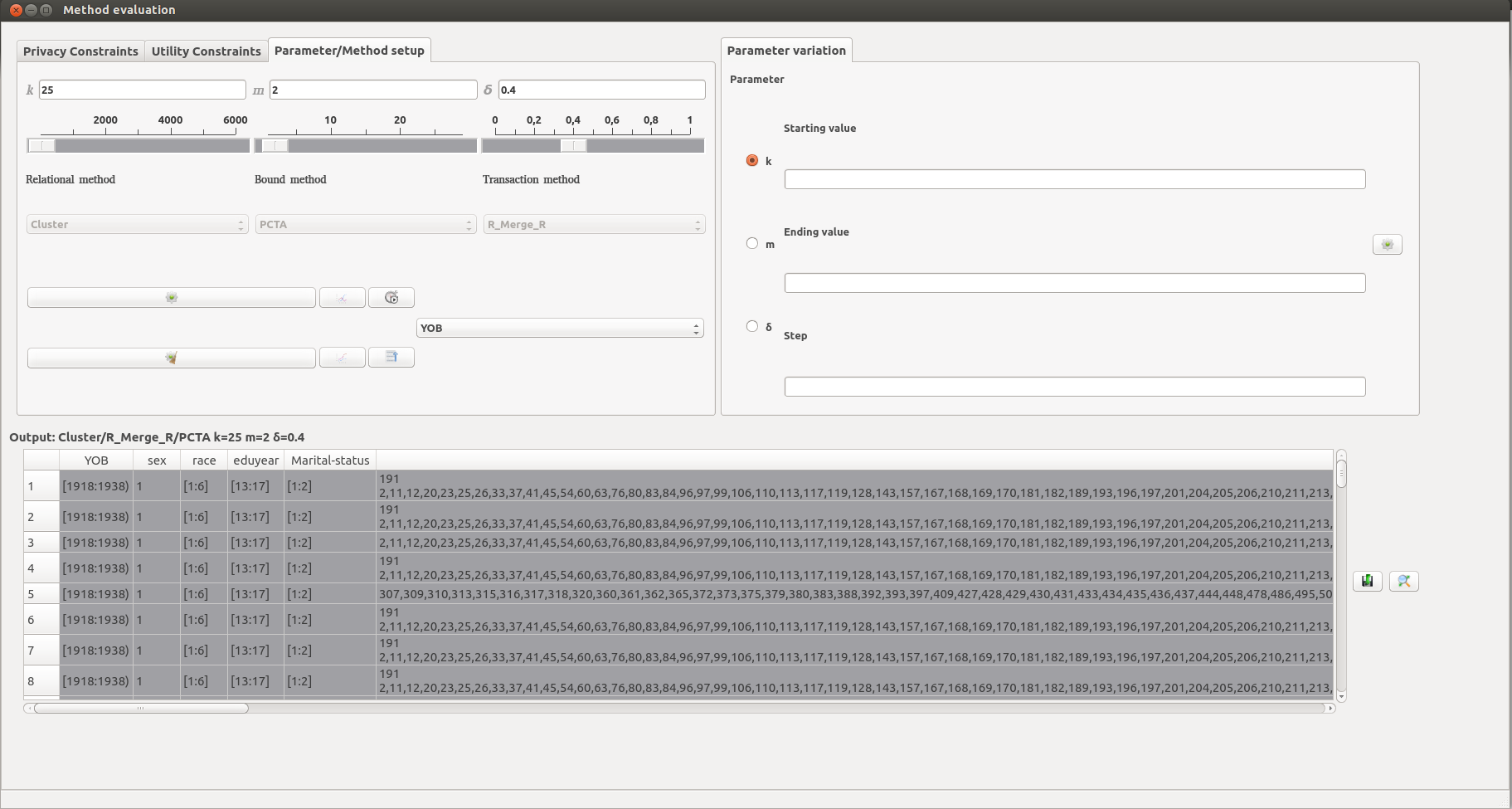
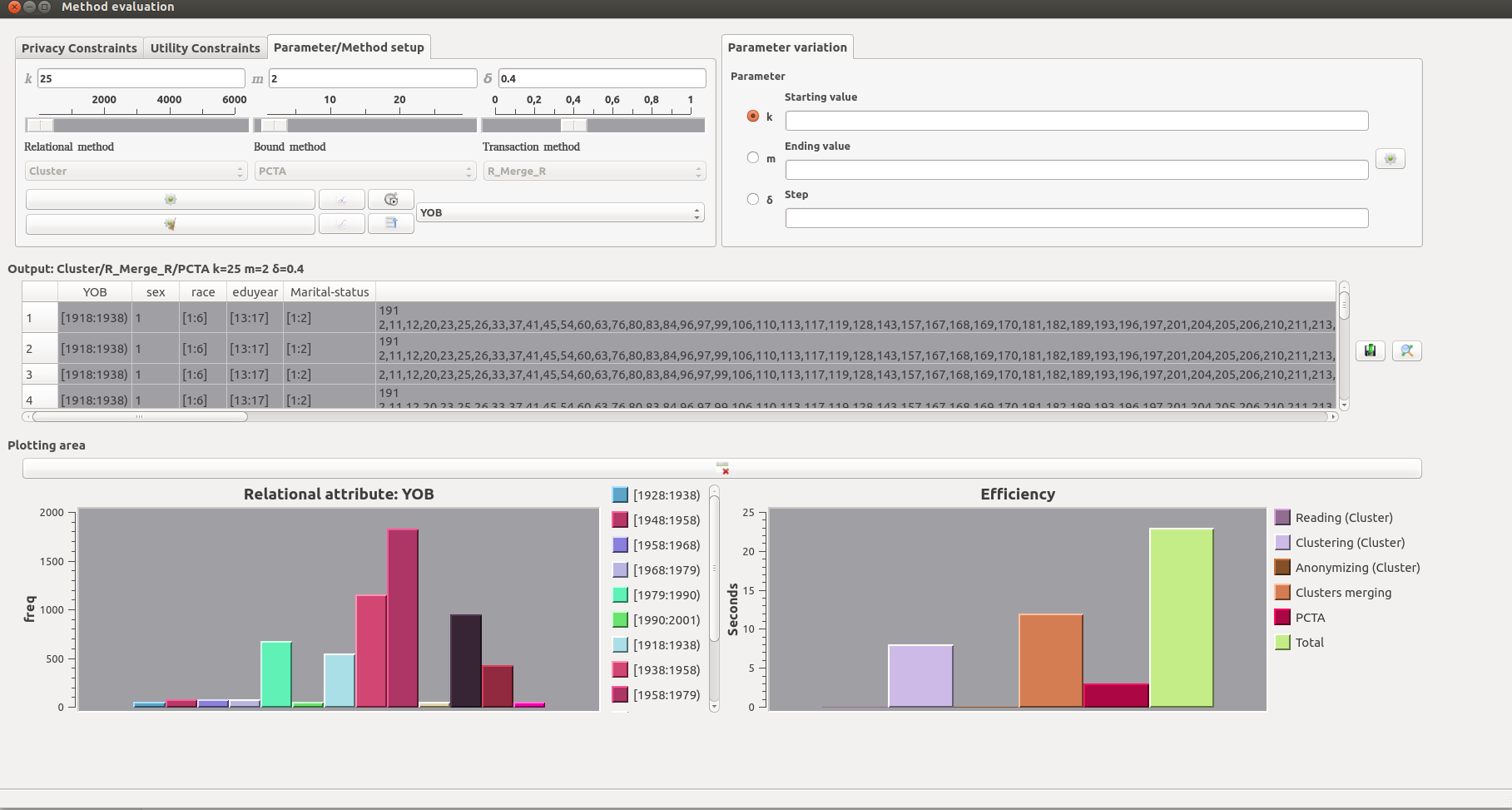 Evaluation screen. Using this interface, users can set the values for parameters k, m and δ, by inputting them directly in the form, or by using the corresponding slider (top-left pane). These parameters affect the efficiency and effectiveness of anonymization algorithms. Then, the user may select two algorithms (one for anonymizing the relational attributes, and one for the transaction attribute), and a bounding method for combining the selected algorithms. The latter is required to anonymize RT-datasets. After anonymization is completed, a message box with a summary of the results is presented to the user and the anonymized dataset is displayed in the output area (middle pane). Finally, the user can select a number of data visualizations. In a similar manner, the user can use the top-mid pane to select a varying parameter, along with its starting value, ending value and step.
Evaluation screen. Using this interface, users can set the values for parameters k, m and δ, by inputting them directly in the form, or by using the corresponding slider (top-left pane). These parameters affect the efficiency and effectiveness of anonymization algorithms. Then, the user may select two algorithms (one for anonymizing the relational attributes, and one for the transaction attribute), and a bounding method for combining the selected algorithms. The latter is required to anonymize RT-datasets. After anonymization is completed, a message box with a summary of the results is presented to the user and the anonymized dataset is displayed in the output area (middle pane). Finally, the user can select a number of data visualizations. In a similar manner, the user can use the top-mid pane to select a varying parameter, along with its starting value, ending value and step.
 This screen shot shows the output of an anonymization process which applied: (a) Cluster in the relational attributes, (b) PCTA in the transaction (set-valued) attribute, and (c) RMERGEr as a bounding method. Parameters k, m and δ were set to 25, 2 and 0.5, respectively.
This screen shot shows the output of an anonymization process which applied: (a) Cluster in the relational attributes, (b) PCTA in the transaction (set-valued) attribute, and (c) RMERGEr as a bounding method. Parameters k, m and δ were set to 25, 2 and 0.5, respectively.
A plot that illustrates the frequency of all generalized values for a relational attribute YOB.
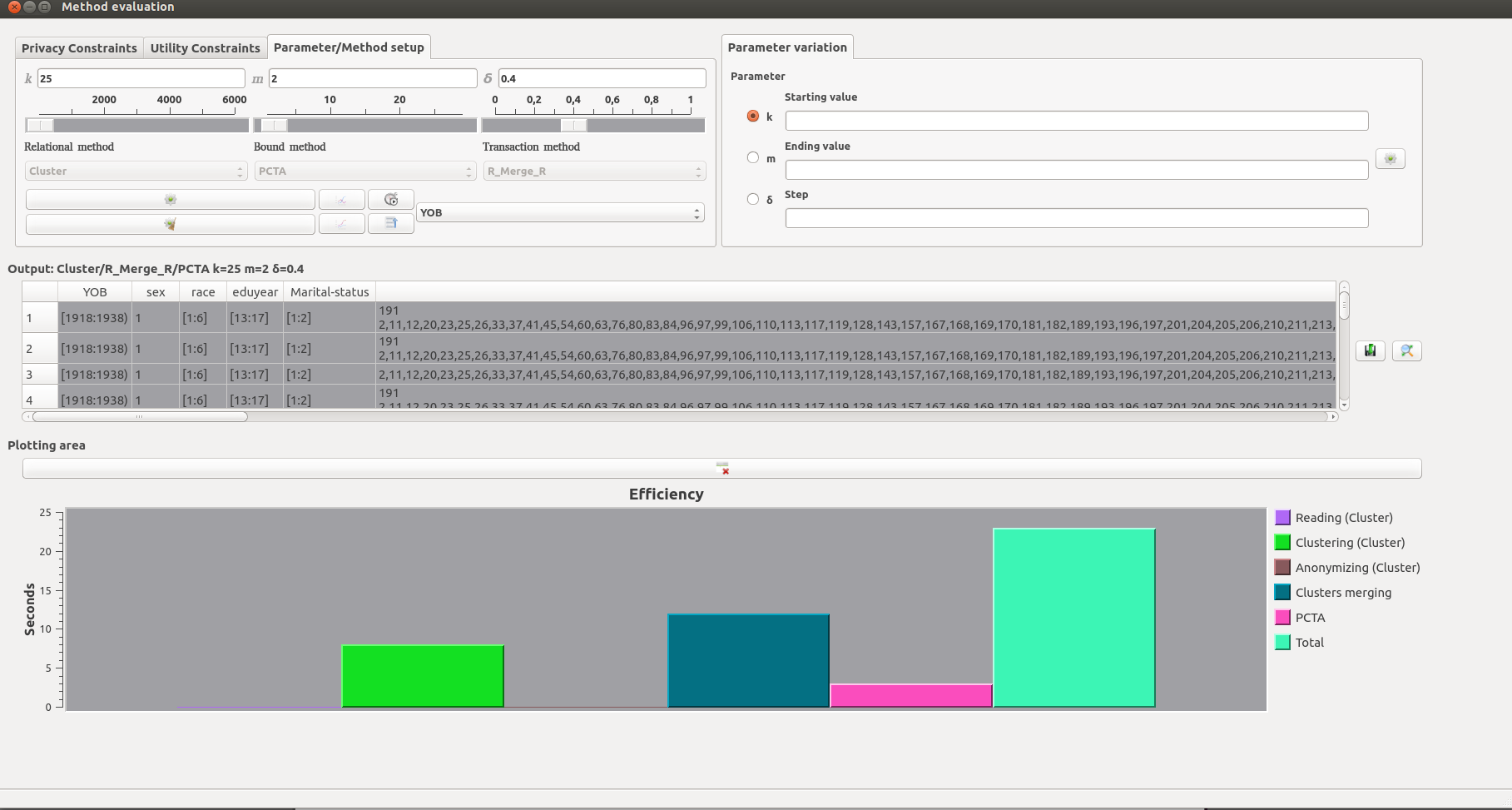 A plot illustrating the time that was needed to execute the anonymization process and each of its different phases.
A plot illustrating the time that was needed to execute the anonymization process and each of its different phases.
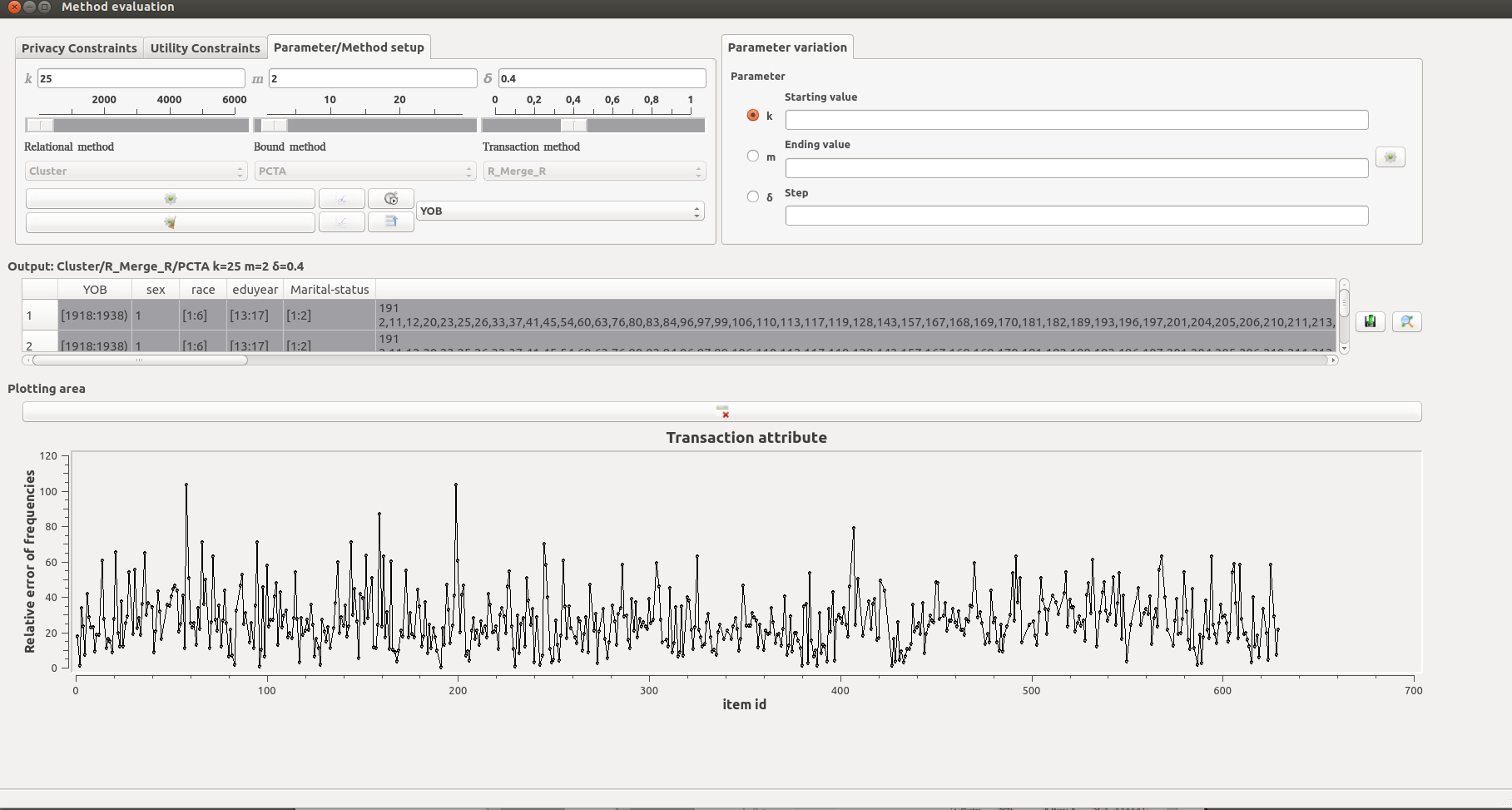 A plot illustrating the relative difference between the frequency of items in the original and the anonymized datasets, for the transaction attribute.
A plot illustrating the relative difference between the frequency of items in the original and the anonymized datasets, for the transaction attribute.
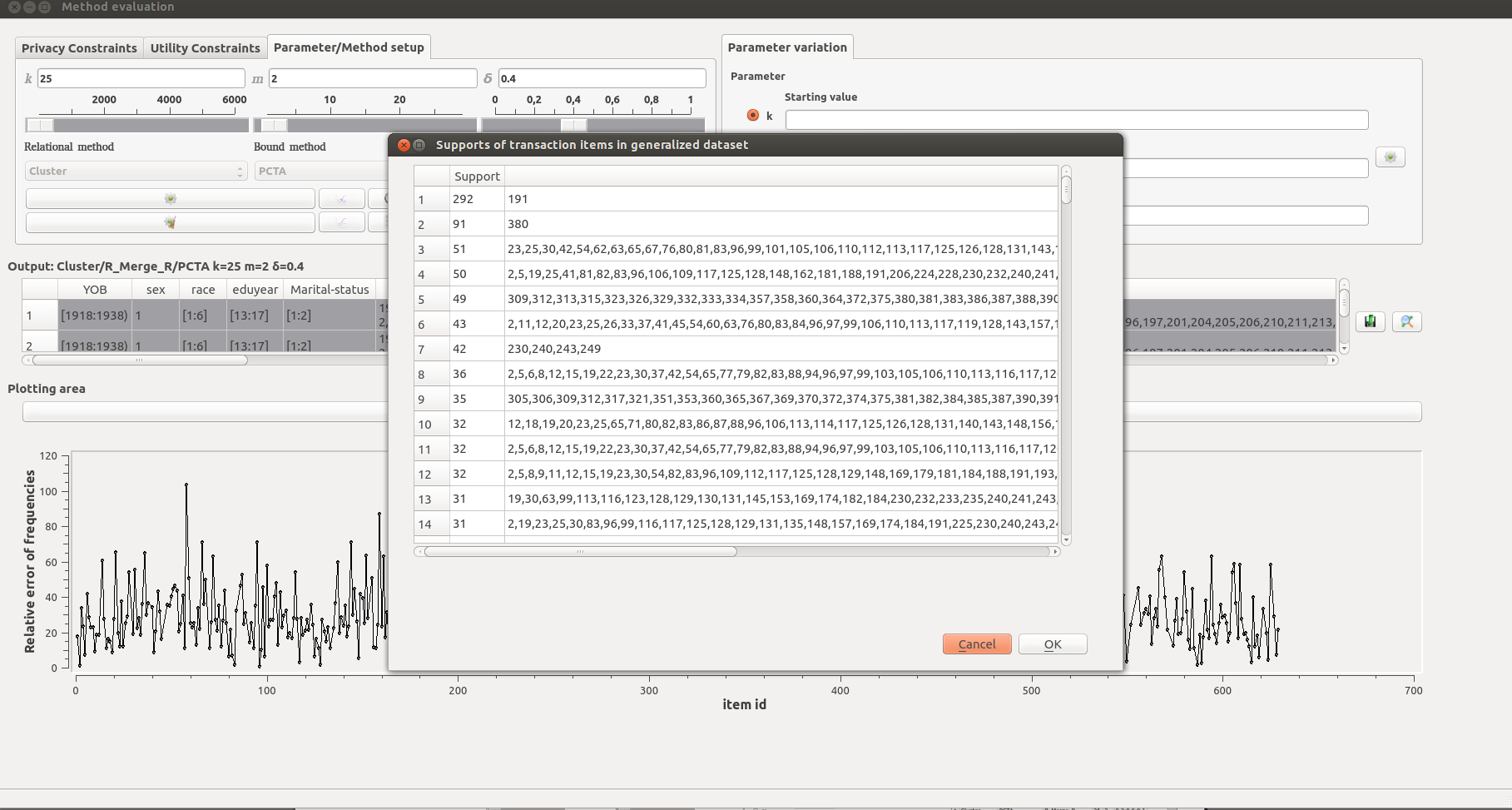 A pop-up menu displaying a table that reports the support (i.e., frequency) of (generalized) items in the transaction attribute, for the anonymized dataset (in decreasing order of support).
A pop-up menu displaying a table that reports the support (i.e., frequency) of (generalized) items in the transaction attribute, for the anonymized dataset (in decreasing order of support).
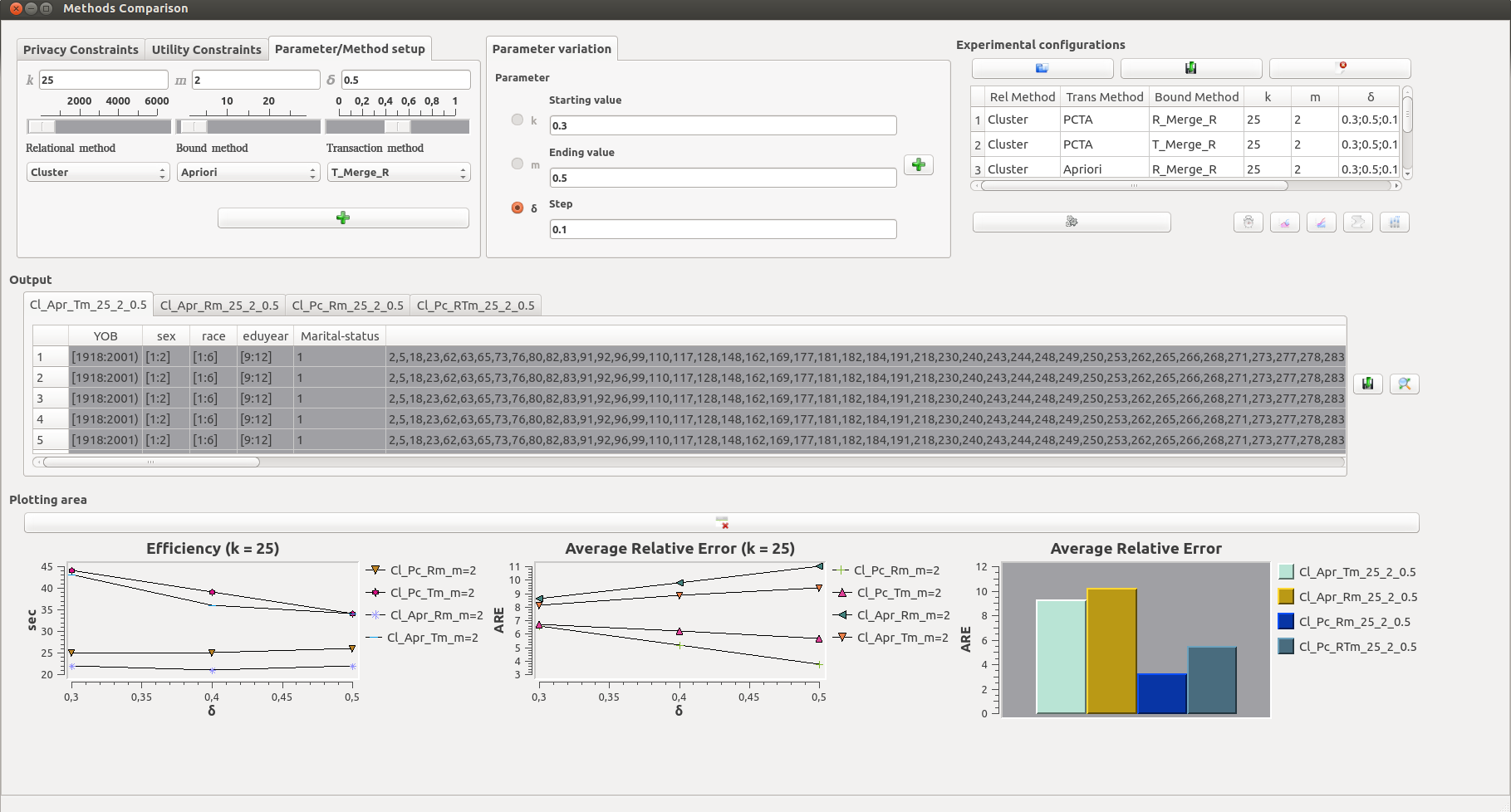 Comparison screen.
This screen allows users to:
Comparison screen.
This screen allows users to:
- select algorithms for anonymizing each type of attributes, as well as a bounding method
- set the values for parameters that will be fixed (top-left pane)
- choose a varying parameter (top-mid pane), along with its start/end value and step
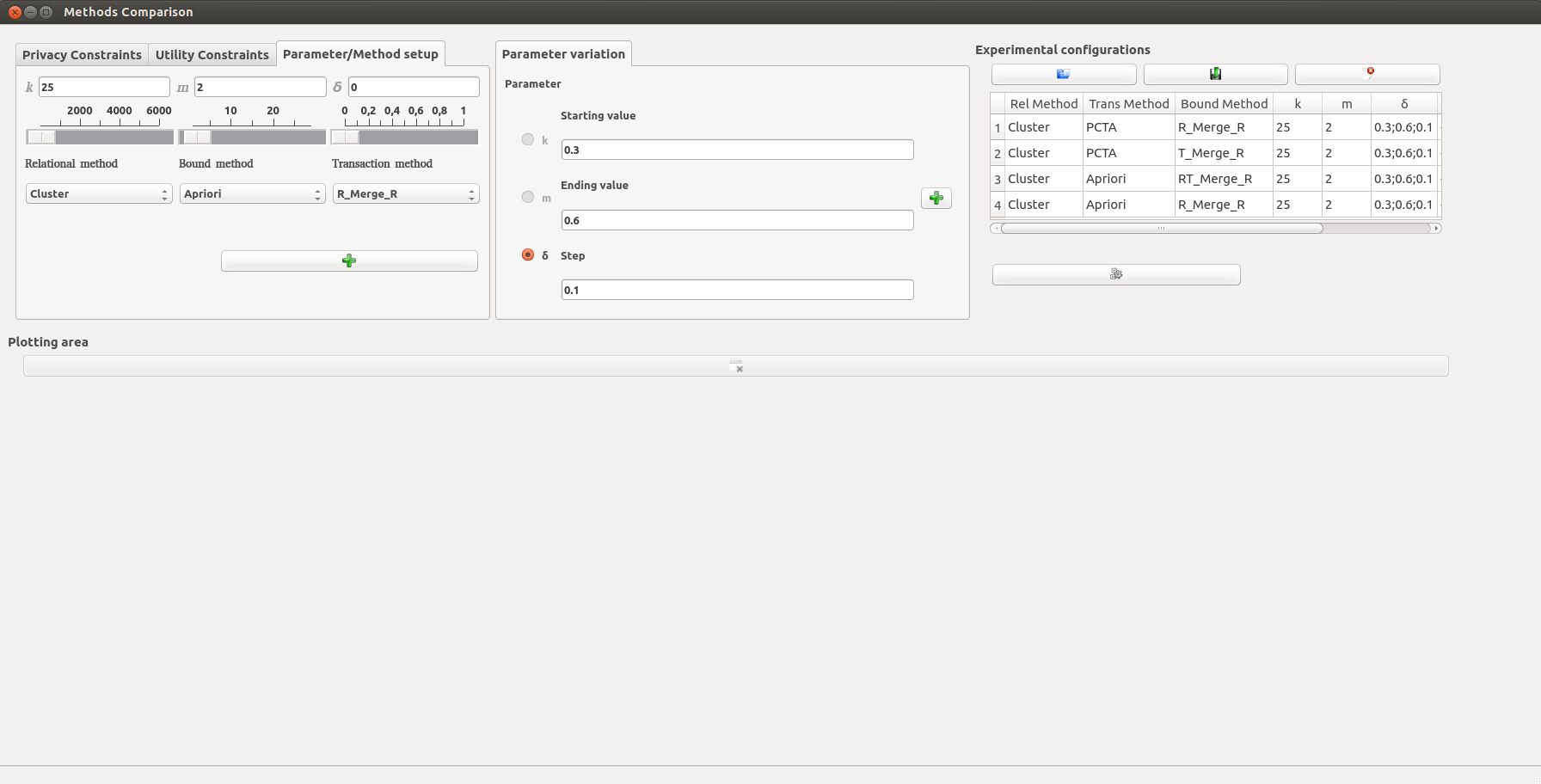 A loaded set of the following configurations:
A loaded set of the following configurations:
- Relational alg.: Cluster, Transaction alg.: PCTA, Bounding method: RMERGEr, k=25 , m=2 ,d=(0.3,0.4,0.5,0.6)
- Relational alg.: Cluster, Transaction alg.: PCTA, Bounding method: TMERGEr, k=25 , m=2 ,d=(0.3,0.4,0.5,0.6)
- Relational alg.: Cluster, Transaction alg.: Apriori, Bounding method: RTMERGEr, k=25 , m=2 ,d=(0.3,0.4,0.5,0.6)
- Relational alg.: Cluster, Transaction alg.: Apriori, Bounding method: RMERGEr, k=25 , m=2 ,d=(0.3, 0.4, 0.5, 0.6)